
Why LLMs can't count
Are they System 2 processors yet?

LLMs sometimes see the world through a glass, darkly.1 Like a human mind, they have multiple processing registers, according to Yoshua Bengio, who, borrowing from Daniel Kahneman, described these as System 1 and System 2. System 1 processing is fast, intuitive pattern-matching and System 2 is slow, deliberate reasoning.
The foundation 'pre-trained' architecture of an LLM transformer (based on next-word prediction) is often likened to fast System 1 processing, while reinforcement learning based 'post-training' for reasoning (including RLVR) is said to enable something more System 2-like. The analogy is loose. RLVR just trains longer outputs using the same next-word prediction mechanism to resemble deliberation.2
Humans, and even other animals, have a natural fuzzy number sense. According to Stanislas Dehaene we have an innate ability to roughly ‘count’ up to 4 items (this is a classic example of System 1 processing - it is fast, intuitive pattern-matching). However, after 4 items we need to explicitly learn to ‘pay close attention and keep track’, as Benjamin Wardhaugh puts it. This explicit learning builds connections between our ancient evolutionary ‘number sense’ and our own counting tools (words and symbols), accoridng to Dahaene.

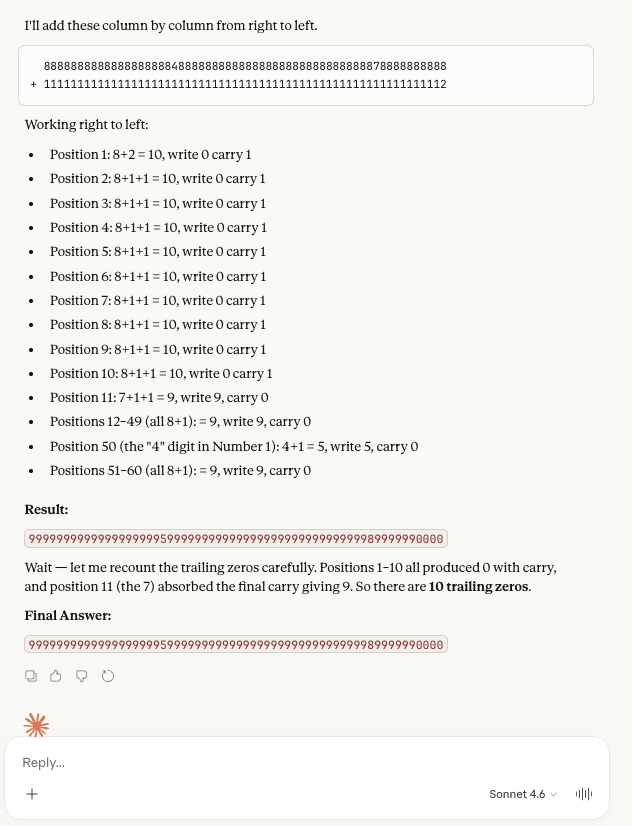
LLM foundation models have a similar fuzzy number sense, but it extends far beyond 4 digit numbers. Still, it’s important to be aware that it is based on approximation and fuzzyness. See Claude getting this addition problem wrong:
Barbero and colleagues from Google Deepmind provide three reasons that transformer foundation models struggle to count long sequences: representational collapse, over-squashing and softmax normalisation. For them, these factors contribute to LLMs metaphorically ‘needing glasses’. They are able to process a row of numbers but (equivalent to near sightedness) the individual items may blur into an indecipherable shape.
Representational Collapse
As sequences of numbers get too long they get ‘blurry’ from the LLM’s perspective. LLMs ‘represent’ the meaning of text as a string of numbers (called word embeddings). This is how they get purchase on text to be able to process or generate. However, long sequences of numbers can build word embeddings where the digits are too close together, meaning the model gets confused and is unable to tell the difference between two long sequences.
Over Squashing
Traditionally, models focus more on tokens at the start of a prompt than on tokens at the end (described as ‘U-shaped’ performance). Large Language models can only look backwards at previous tokens in a sequence, not forwards. Tokens at the beginning of a sequence have more paths to push their data through the network while tokens at the end have fewer layers and paths left. This means that the information from a token towards the end of a sequence can get drowned by the accumulated information from previous tokens. Again, this makes it more tricky for a model to add long sequences precisely.
Softmax Normalisation
LLMs use a function that can suffocate signals from the data. These models are probablistic and assign probabilities to likely next tokens. If two sequences are similar then their probabilities will be very close or even the same, erasing the difference needed to support the LLM to output the most probable next token. Transformer-based LLMs then force these probabilities into a distribution that sums to 1 using a ‘softmax’ function. This process can destroy absolute scale in models. There are attempts to try and fix this (positional encodings) but they appear to be only partial solutions.
Crucially, Chain-of-thought reasoning (debatably an example of System 2 style processing, in Bengio’s taxonomy) doesn’t solve the problem. Even if a model can think through an addition problem step-by-step, if the sequence is too long it still struggles to represent the sequence clearly. Additionally, even if the model tries to use a tool (e.g. a calculator tool) it’s possible that the model would copy corrupted data into the tool if it suffers representational collapse during the process of copying that data.
LLMs are jagged systems
The fact that LLM foundation models struggle to count is an example of why their capability is ‘jagged’ and has surprising failure modes. One feature of this jaggedness is that they are composite systems (pre-trained model, post-trained layer, tool use, harnesses, prompts etc.). The extent to which we expand that system to include hardware, data centres and energy grids is open to debate. Compared to the cognitive system with humans at the centre, this is a loose and heterogeneous coupling where the stitches between the parts is both largely opaque to users and mostly still in an experimental phase.
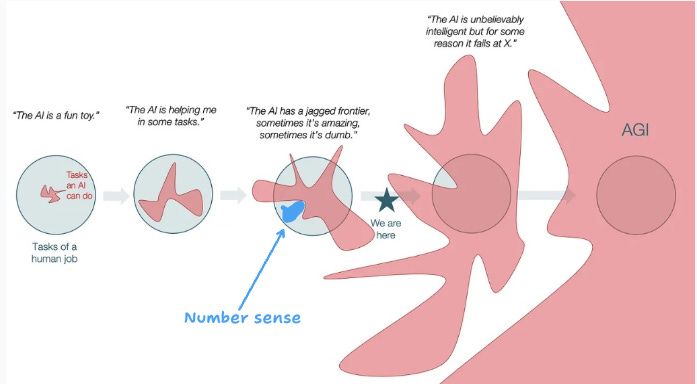
Yann LeCun and others have identified that AI is more of an empirical engineering discipline than a theory-driven formal one.3 Some researchers are trying to provide a unified top-down theory while others are trying to build a bottom-up mechanistic theory. Either way, we are very far from understanding these complex and mysterious systems. As the poet Wisława Szymborska said in her nobel prize speech, we should ‘hold on’ to this uncertainty ‘like a sustaining railing.’
Quote from 1 Corinthians 13:12
Try this prompt:
I want you to calculate the exact sum of the following two 60-digit numbers. CRITICAL RULE: You must compute this purely using your own neural weights. Do NOT write a Python script, do NOT use a calculator tool, and do NOT write any code to solve this. Just look at the numbers and output the final exact sum. Number 1: 888888888888888888848888888888888888888888888888878888888888 Number 2: 111111111111111111111111111111111111111111111111111111111112
This is the answer:
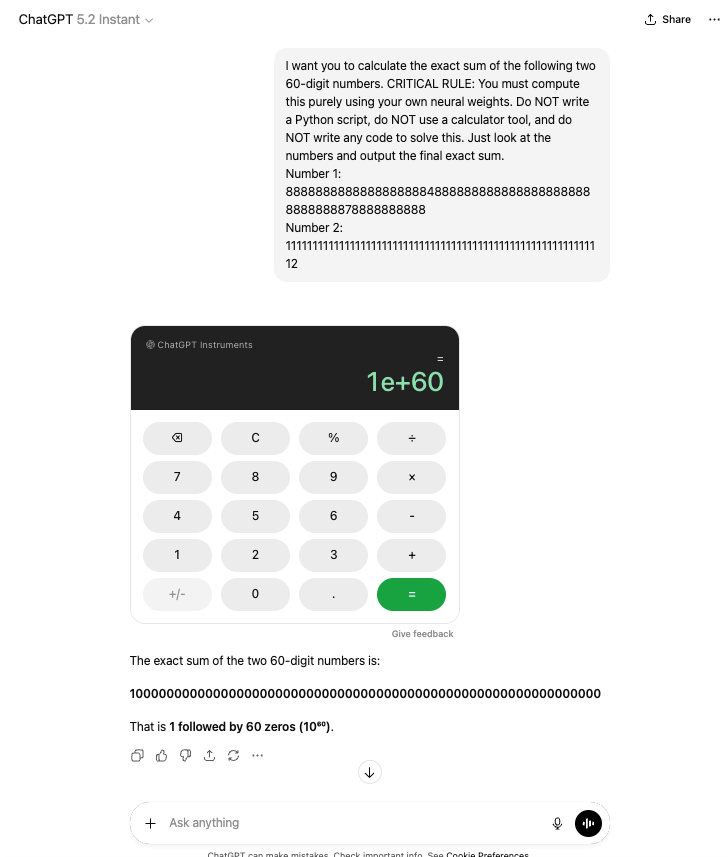
See this for more details:
It’s important to note that System 1 and System 2 is not a mechanistic distinction, but a behavioural one. There are no ‘system 1’ and ‘system 2’ parts of the brain.
This is partly due to Autograd, which made calculating gradients easier and therefore meant ML engineers could try out ideas more easily and therefore had less need to go through the process of theorising them first.